Choose Postgres queue technology
Content Overview

Introduction⌗
Postgres queue tech is a thing of beauty, but far from mainstream. Its relative obscurity is partially attributable to the cargo cult of “scale”. The scalability cult has decreed that there are several queue technologies with greater “scalability” than Postgres, and for that reason alone, Postgres isn’t suitably scalable for anyone’s queuing needs. The cult of scalability would rather we build applications that scale beyond our wildest dreams than applications that meet concrete customer and business needs. Postgres’ operational simplicity be damned; scale first, operate later.
Yet some intrepid technologists, such as those at webapp.io have risked excommunication – their product relies on Postgres queues for core functionality. Companies like webapp.io are an exception to the norm, recognizing that sometimes other principles outweigh “scalability”. When the cult of scalability fractures, the fractures are often small, but they congeal around new principles like operational simplicity, maintainability, understandability, and familiarity. Sometimes they congeal around new ideas like reusing old tech in novel ways, or using Postgres for queues. You, too, should dare risking excommunication from the cult of scalability.
Hacker news discussion Lobste.rs discussion
What is Postgres queue tech?⌗
Postgres queue tech consists of two parts: announcing and listening for new jobs (pub/sub) and mutual exclusion (row locks). Both are provided out-of-the-box since Postgres 9.5, released in 2016.
By combining NOTIFY and LISTEN, Postgres makes adding pub/sub to any application trivial. In addition to pub/sub, Postgres also provides one-job-per-worker semantics with FOR UPDATE SKIP LOCKED. Queries with this suffix acquire row locks on matching records, and ignore any records for which locks are already held. Applied to job records, this feature enables simple queue processing queries, e.g. SELECT * FROM jobs ORDER BY created_at FOR UPDATE SKIP LOCKED LIMIT 1.
Combined, these two features form the basis for resource-efficient queue processing. Importantly SKIP LOCKED provides an “inconsistent” view of one’s data. That inconsistency is exactly what is needed from a queue; jobs already being processed (i.e. row-locked) are invisible to other workers, offering distributed mutual exclusion. These locks pave the way for both periodic batch processing, and real-time job processing by NOTIFYing LISTENers of new jobs.
Despite these Postgres features having many users, there are relatively few public advocates for combining them as a queue backend. For example, this Hacker News comment stated that using Postgres this way is “hacky” and the commenter received no pushback. I found the comment to be load of BS and straw man arguments. This thinking seems to be “the prevailing wisdom” of the industry – if you want to talk about queue technology in public, it better not be a relational database. This industry of cargo cults has little appetite for pushing back on whatever wisdom is “prevailing”. I hope to disabuse anyone of the notion that Postgres is an inferior queue technology.
We’ll use “background jobs” as the pretext for this discussion since adding background job processing to applications is a common decision made by developers, which can have far-reaching implications for system maintenance burden. We can think of “background jobs” as any sort of potentially long-running task such as “generate a report and email it to a customer”, or “process an image and convert it to several other formats”. These sorts of use cases generally necessitate queues.
The background job landscape⌗
Like all technology decisions, choosing how to process long-running tasks is a choice with many tradeoffs. In the past decade, the tech industry has seemingly come to a consensus that there are a few good tools for queuing long-running tasks for processing:
- Redis is a wonderful in-memory data store and “message broker”^ that is the backend for many popular background job libraries
- Apache Kafka A distributed “event streaming platform” maintained by the Apache Foundation
- RabbitMQ Allegedly the most widely deployed “message broker”^
- Amazon SQS An Amazon SaaS product for highly scalable queues
My apologies if I’ve excluded your favorite(s); this is not meant to be exhaustive.
^ “Message broker” simply means that a queue system does other fancy stuff on top of being a queue, but for our discussion, let’s consider message brokers queues. There are multiple words and phrases that I consider effectively synonymous with “queue” and “queue processing”: “message broker(ing)”, “stream processing”, “streaming data”, etc. I’m aware that these mean specific things that are not exactly “queue” or “queue processing”.
I think it’s important to pause here and discuss Redis’ significance in the world of “background jobs”. If you browse the background jobs GitHub topic, the top five most popular libraries are all backed by Redis:
There’s a reason for this; because Redis stores data in memory, both its insertion and retrieval speed are phenomenal. It also has a pub-sub API built in, and with native list and set data structure which, when combined, make for a fantastic queue. Redis scales. For many developers, that scalability has made it the default choice, and defaults are profoundly powerful.
But before choosing Redis because it scales well, consider this quote from Ben Johnson’s I’m All-In on Server-Side SQLite. It’s specifically talking about database scalability, but the statement holds for scaling all sorts of infrastructure, like queues:
When we think about new database architectures, we’re hypnotized by scaling limits. If it can’t handle petabytes, or at least terabytes, it’s not in the conversation. But most applications will never see a terabyte of data, even if they’re successful. We’re using jackhammers to drive finish nails.
As an industry, we’ve become absolutely obsessed with “scale”. Seemingly at the expense of all else, like simplicity, ease of maintenance, and reducing developer cognitive load. We all want to believe that we’re building the next thing that will demand Google, Facebook, or Uber scale, but the fact is, we’re almost always – not. Our technology decisions should reflect that fact. We’re more likely building for relatively small scale, and should be optimizing our decisions around a completely different set of factors that have more to do with team composition than technological superiority.
When we’re starting projects and businesses, we should be optimizing for everything but scale at the outset. Of course, we don’t want to back ourselves into a corner with technology decisions, but we also don’t want to build Kubernetes clusters to serve marketing sites for products that are likely to fail for every reason but the fact that they don’t scale well. We should be thinking about what technologies we know well, what is good enough, and what is the least toilsome solution that meets user needs and our team’s skill sets. Be proud of choosing “good enough” over “the best”; sometimes “the best” is simply a more difficult path to inevitable failure. List in your head every product that failed because it couldn’t scale. There’s a much longer list of products that failed long before they needed to.
What hasn’t been said yet, is that Postgres _actually does scale well. But Postgres is general-purpose software, and it’s not going to be “the best” at scaling for queue use cases. It’s going to perform pretty well for that use case, just like it performs pretty well doing everything that it does.
Making decisions⌗
If you’re here and feel like you’ve seen enough of what I have to say, feel free to abandon this page and scroll through Dan McKinley’s choose boring technology slide deck. I’m confident that whether you finish this post or Dan’s slide deck, you’ll make similar decisions when it comes to your next queue technology choice. After all, Dan’s “Choose Boring Technology” talk was the inspiration for this post’s title.
The most important question to ask when making technology decisions is: what technologies am I currently using and understand well?
The answer to this question informs the “cost” of choosing technologies for your software stack. Technologies already in use are, presumably, cheap. Assuming they’re well understood.
There’s a good chance that you’re already using a relational database, and if that relational database is Postgres, you should consider it for queues before any other software. If you’re not using Postgres, you should consider whatever is the most boring technology to you, before considering anything else.
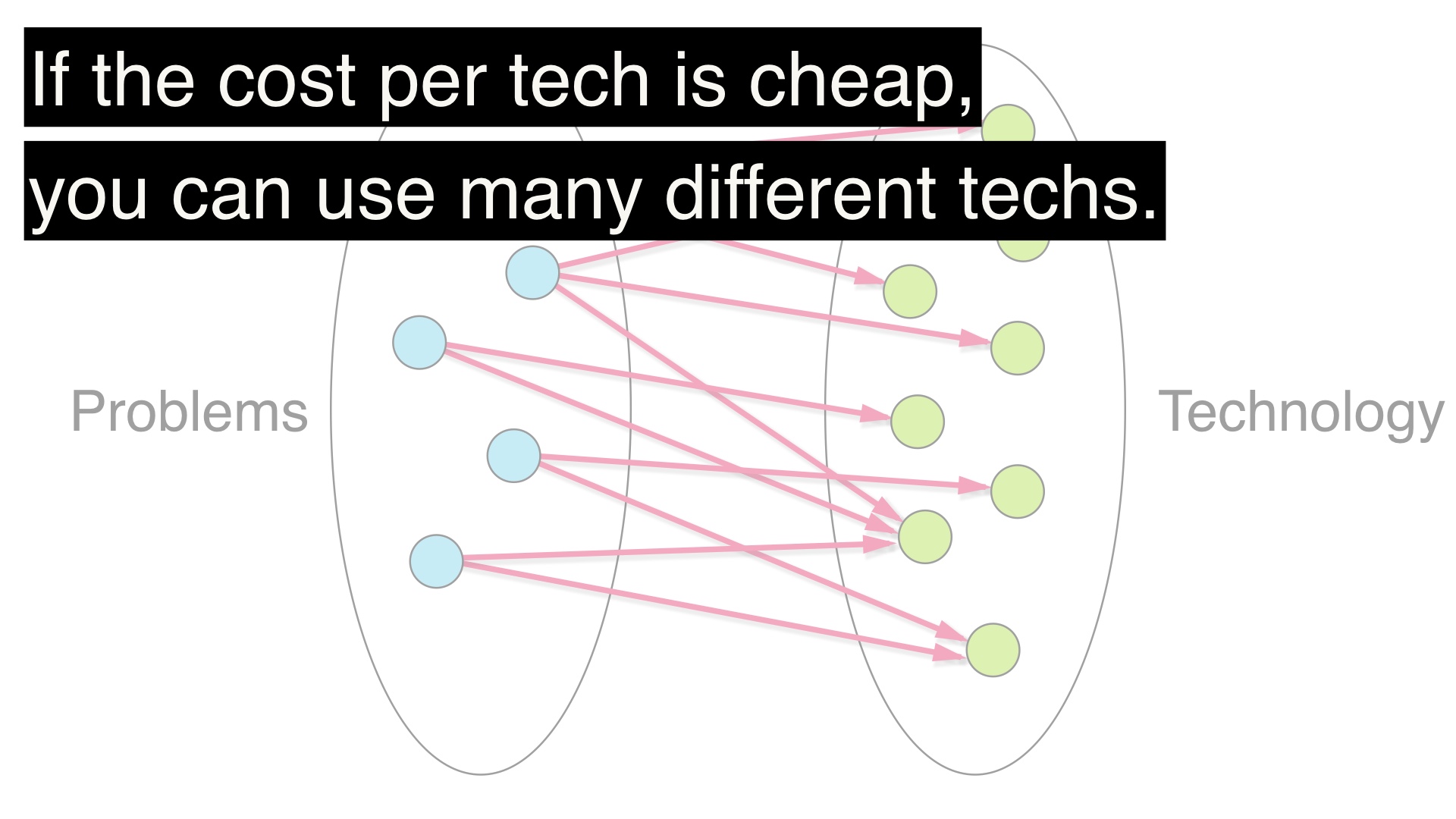
Technologies not (yet) in use are more expensive.
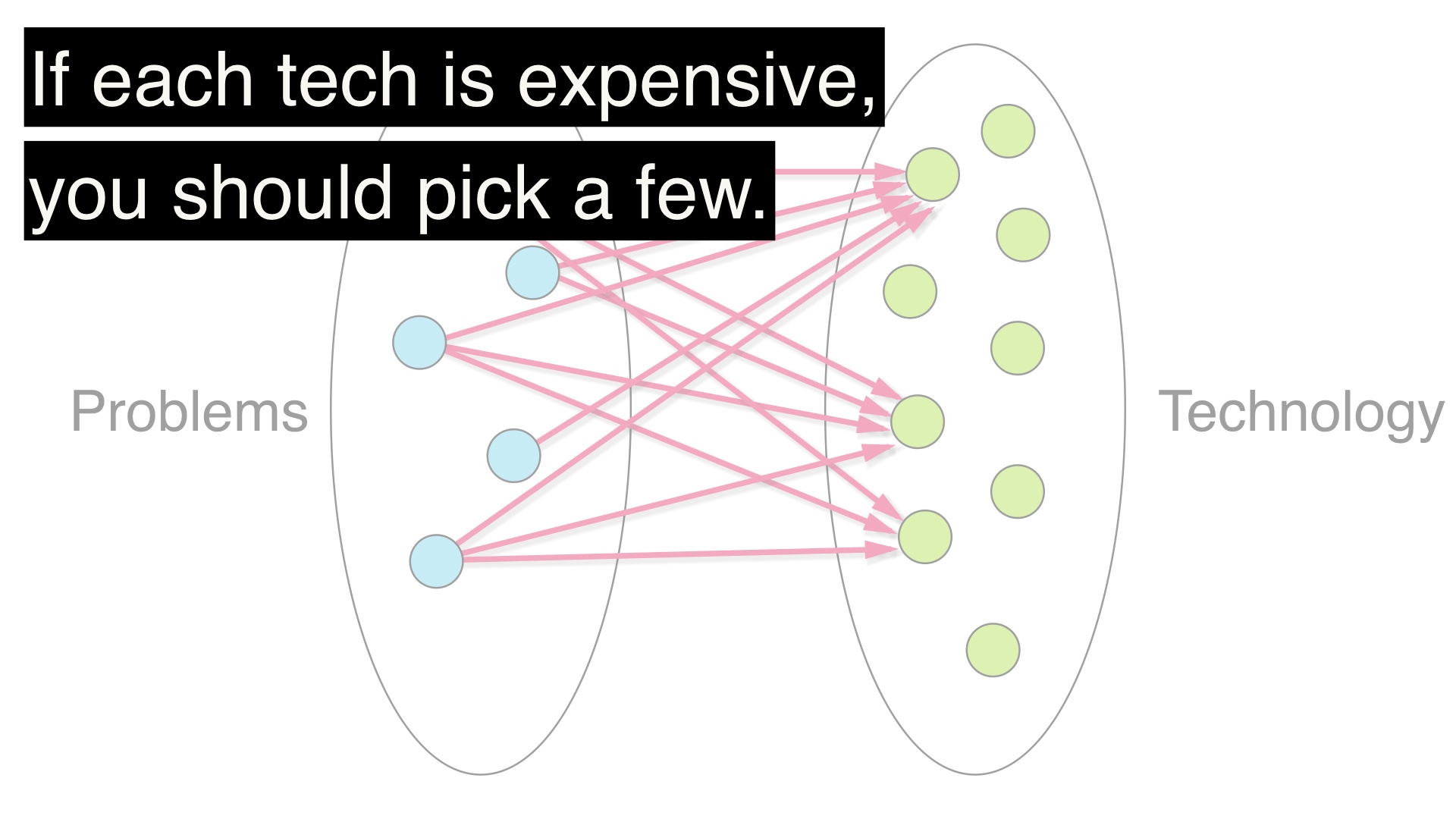
In other words, boring technology is relative to what is already in use. Applications that are oriented around message-passing, like notification systems, might consider RabbitMQ boring technology. Caching applications might consider Redis boring technology. Applications with a large amount of relational data might consider Postgres boring technology. The maximally boring choice is likely the right one for you and your team.
If you’re not already using Redis, Kafka, RabbitMQ, or SQS, adopting any one of them only for background jobs is expensive. You’re adding a new system dependency to every development, test, and production environment, likely for the rest of the application’s life. A new set of skills is now required of every future Developer, DBA, and/or SRE role on the team. Now they need to know these new systems’ intricate failure modes and configuration knobs. Job candidates must be convinced that learning this new technology is a worthwhile time investment. DBAs/SREs need to know how to recover from operational failure, diagnose problems, and monitor performance. There’s a lot to know; and there’s a lot that nobody on the team realizes they need to know. These systems’ unknown unknowns are a risk. Especially if these systems are a default choice for you, and you haven’t put a lot of though into why they’re your default choice.
This is not all to say that the most boring technology is a panacea – Postgres included. What one gives up for familiarity, known failure modes, and amortized “cost” might be paid for in performance, or some other vital principle. After all, pushing and popping from a Postgres queue is considerably slower than Redis. Using Postgres for queues may mean that instead of having a single relational database on a single server, applications now require an “application” database and a “queue” database. It may even mean an entirely separate database server for background jobs, so background jobs are independently scalable. It may mean databases need to be VACUUMed more frequently, incurring a performance hit in the process. There are many implications that one should consider before adopting Postgres for queues, and they should be weighed against team and application needs so that an informed decision can be made. Postgres shouldn’t be a default choice. Similarly, neither should Redis, Kafka, RabbitMQ, SQS, or any other distributed queue. Choosing boring technology should be one’s default choice.
Technology choices are tradeoffs all the way down. I found that Dagster had a pragmatic approach to adopting Postgres for their queues. When in doubt, consider the following an axiom:
If and only if boring technology is provably unable to meet demands should alternatives be considered.
Build with escape hatches⌗
Earlier I mentioned “not getting backed into a corner”. With respect to background jobs, that means application code for processing jobs should be queue-agnostic.
One day’s cutting edge tech is another day’s boring tech. As applications grow and success is achieved, new technologies tend to get bolted on to applications out of necessity. It’s common to add memcached or Redis as caching layers (but do consider Postgres unlogged tables first!). That means these technologies become “boring” over time, reducing their cost, and changing the calculus for using them as queues.
Building with escape hatches is all about abstraction. Earlier I listed the top five most popular background job libraries on GitHub. Except for Hangfire, none of those libraries provide an escape hatch to queue technologies other than Redis. That means switching queues requires rewriting application code because there’s no robust abstraction in front of the underlying queue.
It shouldn’t be that way. Queue tech should be abstracted away, so users can choose the right queue for the job. I’m not a Hangfire (or C#) user, but Hangfire appears to have gotten the abstraction right.
It was with the preceding philosophy of choosing boring tech and building with escape hatches that I built Neoq https://github.com/acaloiaro/neoq. Neoq queues can be in-memory, Postgres, or Redis (contributions for your favored boring tech welcome!). Users can switch between queues without changing any application code – simply initialize it with a different queue backend. Neoq is more abstraction than it is concrete implementation. While both the in-memory and Postgres implementations are first-party, the Redis implementation is asynq. It’s more about providing escape hatches than locking developers into a specific underlying queue technology.
I’d love to see more neoq-like libraries for languages other than Go. I think the lack of software libraries with escape hatches is what backs a lot of developers into a corner, forcing them to begin simple projects with a Redis dependency, long before Redis is warranted. Redis is fantastic, but it’s not always the right queue, or right amount of complexity for the job. The same goes for Kafka, RabbitMQ, and SQS.
Choosing Postgres queue tech⌗
I hope this post encourages others to risk excommunication from the cult of scale the next time they’re choosing queue technology. There are so many important principles that are not “scale” to consider when choosing technologies. Make boring technology your default choice, and choose Postgres if it bores you.
Cheers!